Die Lösung einer Programmieraufgabe (=Algorithmus) wird in Form eines Programms realisiert. Teillösungen werden dabei als Prozeduren (Unterprogramme) formuliert, welche nach Beendigung ihrer Arbeit zum aufrufenden übergeordneten Programm zurückkehren. Damit die Leistungen des Betriebssystems problemlos in Anwenderlösungen eingebunden werden können, sind sie ebenfalls als Prozeduren realisiert.
Die Codierung eines Programms erfolgt dabei in einer höheren Programmiersprache (wie z.B. C, C++ oder Java; es existiert allerdings eine Unzahl von Programmiersprachen, die zum Teil erheblich von der Philosophie von C abweichen). Die Übersetzung vom für den Menschen lesbaren Programmtext einer Programmiersprache in die Sprache der jeweiligen CPU (Maschinensprache) erfolgt durch einen Compiler oder in manchen Fällen durch einen Interpreter.
Ein in Maschinensprache übersetztes und von der CPU ausführbares Programm enthält alle Teile (Hauptprogramm, Unterprogramme = Prozeduren) und besteht aus:
Der Begriff Prozess wurde von den Betriebssystementwicklern schon relativ früh verwendet. Eine ähnliche Bedeutung wie Prozess wurde auch dem Begriff Task gegeben. Allerdings gibt es keine allgemeine und eindeutige Festlegung, was man unter "Prozess" wirklich verstehen müsste. Die wichtigsten Bedeutungen sind etwa:
Viele andere Definitionen existieren; am häufigsten versteht man unter einem Prozess ein Programm, das gerade ausgeführt wird.
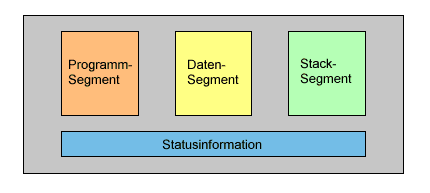
Zu einem Prozess gehören jedenfalls der Code und die Daten des Programms. Als weitere, wichtige Komponente, die zu den Daten gehört, wird beim Ablauf eines Programms ein Stack aufgebaut. Es handelt sich dabei um einen Datenbereich, der über eine besondere Zugriffsregelung verfügt: Jene Daten, die zeitlich zuletzt auf den Stack geschrieben werden, müssen auch zeitlich vor den Daten gelesen werden, die zu einem früheren Zeitpunkt geschrieben worden sind (Prinzip "Last In, First Out": LIFO).
Somit lässt sich ein Prozess modellhaft folgendermaßen darstellen:
Da ein Prozess unter der Kontrolle des Betriebssystems ausgeführt wird, muss das Betriebssystem gewisse Informationen über den Prozess kennen. Das ist dann besonders wichtig, wenn es sich um ein Multi-Task-Betriebssystem handelt (was als Regelfall gelten kann). Deswegen legt das Betriebssystem zu jedem Prozess einen Prozesssteuerblock (process control block = PCB oder task control block = TCB) in der Prozesstabelle ab, der alle notwendigen Informationen über einen Prozess enthält, z.B.:
Im Zusammenhang mit dem Begriff "Prozess" sind die folgenden Punkte wichtig:
Es kommen immer mehr Rechnermodelle auf den Markt, die mit mehr als einer CPU ausgerüstet werden. In den meisten Fällen handelt es sich dabei um symmetrisches Multiprocessing (SMP), wobei jeder CPU die gleichen Aufgaben zugeteilt werden können und keine "Spezial-CPUs" für jeweils eine bestimmte Tätigkeit (Rechnen, Ein-/Ausgabe etc.) existieren. Moderne Betriebssysteme müssen daher die Möglichkeit berücksichtigen, dass ein Rechner mehr als eine CPU besitzt.
Wenn die Rechentätigkeit auf mehrere CPUs aufgeteilt werden kann, so bedeutet das nicht nur einen generell höheren Durchsatz für die Gesamtheit der im Rechner vorhandenen Prozesse, sondern auch neue Möglichkeiten für den Ablauf innerhalb eines einzigen Programmes: Oft steht man als Anwendungprogrammierer vor der Aufgabe, mehrere Abläufe innerhalb eines Programmes zu steuern; ein gutes Beispiel ist in diesem Zusammenhang ein Textverarbeitungsprogramm, das zunächst natürlich die Texteingabe des Benutzers entgegennehmen muss. Die Darstellung des Textes erfolgt in graphischer Form über irgend ein graphisches Benutzerinterface (Macintosh, Windows, ). Dabei muss bereits das Seitenlayout (zumindest der Zeilenumbruch) berechnet werden, bevor eine Ausgabe auf dem Bildschirm erfolgen kann. Weiters wünscht man sich als Benutzer beispielsweise einen im Hintergrund automatisch arbeitenden Seitenumbruch, möglicherweise auch eine automatische Rechtschreibprüfung. Alle diese Tätigkeiten müssen innerhalb eines einzigen Programmes durchgeführt werden, möglichst so, dass die Reaktionszeit auf die Eingabe nicht spürbar vergrößert wird. Man erkennt deutlich, dass es mehrere nahezu unabhängige Abläufe innerhalb eines Textverarbeitungsprogrammes gibt. Es ist aber dennoch unpraktisch, diese einzelnen Abläufe in voneinander völlig getrennte Prozesse aufzuteilen, weil der Zugriff auf einen gemeinsamen Datenbestand von getrennten Prozessen aus schwieriger und zeitaufwendiger ist als innerhalb eines einzigen Prozesses. Gesucht ist also die Möglichkeit, innerhalb eines Prozesses mehrere Abläufe programmieren zu können, deren Zuteilung an die CPU vom Betriebssystem gesteuert wird. Die einzelnen Abläufe werden mit dem englischen Begriff "Threads" bezeichnet. Es liegt auf der Hand, dass Programme, die mehr als einen Thread besitzen, besonders effizient auf Rechnern laufen, die mehr als eine CPU besitzen, denn dann können die einzelnen Threads wirklich gleichzeitig abgearbeitet werden.
Ein modernes Betriebssystem sollte jedenfalls die Möglichkeit, mehr als einen Thread innerhalb eines Prozesses ablaufen lassen zu können, zur Verfügung stellen, gleichgültig, wie viele Prozessoren der Rechner besitzt. Da mehrere Threads innerhalb eines Prozesses denselben Adressraum besitzen, muss bei der Verwendung gemeinsamer Datenbestände besonderes Augenmerk auf einen synchronisierten Zugriff gelegt werden. Das Betriebssystem muss den synchronisierten Zugriff ermöglichen, indem es verschiedene Mechanismen bereitstellt, die den Ablauf einzelner Threads gegebenenfalls unterbrechen, bis ein bestimmter Datenbereich von einem anderen Thread wieder freigegeben wird.
Gemeinsam genutzte Datenbereiche können aber auch in versteckter Form innerhalb eines einzelnen Prozesses existieren; besonders im Bereich der Ein-/Ausgabe werden Routinen benützt, die für die Durchführung der Ein-/Ausgabe lokale Variablen benötigen. Wenn solche Variablen in einem für den Prozess globalen Datenbereich angelegt werden und ein Thread gerade solche Variable verwendet, wenn er von einem anderen Thread unterbrochen wird, der ebenfalls auf diese Variablen zugreifen möchte, führt dies unweigerlich zur Zerstörung der Datenkonsistenz. Routinen mit diesen Eigenschaften werden als non-reentrant bezeichnet, weil sie nicht unterbrochen und von einem anderen Thread begonnen werden dürfen (vgl. Prozess-Synchronisierung weiter unten!).
In der folgenden Aufstellung werden die verschiedenen Zustände, in denen sich ein Prozess befinden kann, beschrieben. Für Betriebssysteme, die Threads unterstützen, muss der Begriff "Prozess" durch "Thread" ersetzt werden.
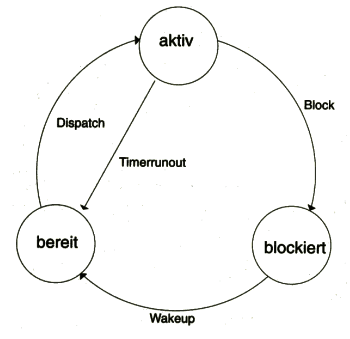
Während seiner Abarbeitung kann ein Prozess verschiedene Zustände einnehmen, die mit den folgenden Begriffen bezeichnet werden:
Betrachten wir der Einfachheit halber die Situation in einem Rechner mit einer einzigen CPU; nur ein einziger Prozess kann zu einem bestimmten Zeitpunkt running sein, zahlreiche andere hingegen ready, und wieder andere könnten blocked sein. Das Betriebssystem wird daher eine Liste der lauffähigen Prozesse (ready list) und eine Liste der blockierten Prozesse (blocked list) führen.
Ein spezieller Teil des Betriebssystems, der Scheduler, teilt den Prozessen die CPU zu. Für die Zuteilung existieren unterschiedliche Algorithmen, die alle das Ziel haben, die CPU möglichst gerecht unter allen Prozessen aufzuteilen. Für die Steuerung der Zeitscheiben ist ein in regelmäßigen Zeitabständen auftretender Harwareinterrupt notwendig, d.h. der Scheduler wird regelmäßig aufgerufen.
 |
|
Neben dem PCB werden noch weitere, zum Prozess gehörige Daten geführt, auf die er aber nur im Zustand running Zugriff hat. Dazu gehören u.a.:
In modernen Betriebssystemen gibt es noch eine Reihe weiterer Zustände, die man von den oben erwähnten drei unterscheidet; ohne die drei Prozesszustände running, blocked und ready lässt sich ein (Multitasking-)Betriebssystem jedoch nicht realisieren.
Unter dem Begriff Kontextwechsel oder Context Switch versteht man einen Vorgang, bei dem die Bearbeitung des aktuellen Prozesses (oder auch Threads) durch einen Interrupt unterbrochen wird und zu einem anderen Prozess bzw. Thread gewechselt wird. Dabei wird der Kontext (im Wesentlichen die Prozessor-Register) des aktuellen Prozesses/Threads gesichert und der Kontext des folgenden wiederhergestellt.
Um welchen Interrupt es sich dabei handelt, ist nicht festgelegt. In sehr vielen Fällen wird es sich um den Interrupt des Zeitgeberbausteins (timer interrupt) handeln. Die zugehörige Interrupt-Serviceroutine (ISR) wird dann die aktuelle Uhrzeit, die das Betriebssystem natürlich vorrätig halten muss, aktualisieren. Jedenfalls wird durch einen (im Grunde beliebigen) Interrupt das Betriebssystem "aufgeweckt" (es erfolgt ein Wechsel vom User-Mode in den Kernel-Mode der CPU); es kann somit überprüfen, ob neben der Interrupt-Serviceroutine noch andere Tätigkeiten anstehen. Wenn die für einen Prozess oder Thread vorgesehene Zeit verstrichen ist, wird das Betriebssystem (genauer der Scheduler) einen Kontextwechsel durchführen, um einen anderen Prozess bzw. Thread der CPU zuzuteilen.
Hauptfunktionen eines Betriebssystems
Man unterscheidet drei wesentliche Funktionen, die ein (Multitasking- bzw. Multiuser-)Betriebssystem durchführen muss. Diese Funktionen müssen im privilegierten Modus der CPU (kernel mode) ablaufen:
Interrupts treten immer dann auf, wenn von einem Peripheriegerät (z.B. Festplattencontroller, Tastatur, Zeitgeberbaustein, Netzwerkinterface) ein elektrisches Signal an die CPU geliefert wird. Das Peripheriegerät fordert damit eine Aktion des Betriebssystems an. Das kann im Falle des Festplattencontrollers ein Hinweis sein, dass eine früher (vom Betriebssystem) eingeleitete Ein-/Ausgabeoperation abgeschlossen worden ist oder im Fall des Zeitgeberbausteins, dass eine bestimmte Zeitspanne seit dem letzten Interrupt dieses Bausteins verstrichen ist; das Betriebssystem kann dadurch verschiedene Zeitinformationen (z.B. Systemuhrzeit) auf den neuesten Stand bringen.
Eine Routine, die im Rahmen des Betriebssystems im Kernel Mode durch einen Interrupt (automatisch) aufgerufen wird, heißt Interrupt Service Routine.
System Calls werden benötigt, um "normalen" Programmen, also Programmen, die im User Mode laufen, Funktionen des Betriebssystems zur Verfügung zu stellen. Auf diese Weise kann z.B. eine Ein- oder Ausgabeoperation durch ein Programm angestoßen werden. Alle für die Ein- oder Ausgabe notwendigen Berechnungen werden dann im Kernel Mode (also vom Betriebssystem) durchgeführt. Diese Berechnungen sind spezifisch für die Art des jeweiligen Ein-/Ausgabegeräts (Peripheriegeräts) und laufen in speziellen Routinen ab, die Treiber genannt werden. Auf diese Art bleiben die Eigenheiten der jeweiligen Peripheriegeräte den Programmierern von User-Mode-Programmen (glücklicherweise) erspart.
Wenn ein Programm im User Mode einen Maschinenbefehl ausführen soll, der nicht erlaubt ist (ein mögliches Beispiel wäre eine Division durch Null) oder wenn während der Abarbeitung eines Maschinenbefehls ein Page Fault auftritt, muss ebenfalls die Hilfe des Betriebssystems in Anspruch genommen werden. Solche Situationen werden als Traps, Faults oder Exceptions bezeichnet. Man spricht in diesen Fällen auch von einem Software Interrupt. Das Betriebssystem muss auch auf solche Ereignisse reagieren - entweder, indem das betreffende Programm abgebrochen wird oder indem geeignete Maßnahmen eingeleitet werden, um die Fehlersituation zu beheben.
Alle drei Vorgänge (Interrupts durch ein elektrisches Signal, das von einem Peripheriegerät an einen Pin der CPU geleitet wird; System Calls und Exceptions) führen dazu, dass die CPU vom User Mode in den Kernel Mode gelangt. Nur dadurch kommt das Betriebssystem in die Lage, Operationen auszuführen. Im weiteren Sinn werden sowohl Interrupts als auch System Calls und Exceptions zum "Interrupt Handling" gezählt.
Zunächst wird das Betriebssystem die Aufgabe erledigen, die zur Aktivierung des Kernel Mode geführt hat. Außerdem kann es aber bei dieser Gelegenheit Aufgaben für Scheduling und Speicherverwaltung (memory management) ausführen.
Wenn das Betriebssystem alle anstehenden Operationen erledigt hat, muss als letzte Aktion wieder der User Mode der CPU eingestellt werden. Das erfolgt durch eine privilegierte Anweisung (wir sind ja noch im Kernel Mode!), die oft als Return-from-interrupt bezeichnet wird.
Ein Mikrokernel besitzt nur die für ein Betriebssystem unbedingt notwendigen Funktionen: seine Tätigkeit ist beschränkt auf die Verwaltung der Prozesse (Scheduling, Synchronisation, Kommunikation) sowie die Speicherverwaltung; natürlich muss ein Mikrokernel auch auf Interrupts reagieren, die Weiterverarbeitung der Interrupts kann jedoch in Routinen erfolgen, die nicht mehr zum Kernel gehören (d.h. die Treiber müssen nicht mehr im privilegierten Kernel-Modus der CPU laufen). Das ist der wesentliche Unterschied zu einem so genannten monolithischen Kernel, der sämtliche Treiber beinhaltet.
Der Vorteil eines Mikrokernels besteht darin, dass die Beschränkung auf die notwendigsten Funktionen gleichzeitig auch eine deutliche Reduktion des Kernel-Codes bedeutet. Das wirkt sich vorteilhaft auf die Übersichtlichkeit des Codes aus, was in der Regel auch zu korrekterem Code führt. Ein weiterer Vorteil ist in der prinzipiellen Austauschbarkeit der Treiber zu sehen, während bei einem monolithischem Kernel eine Änderung eines Treibers zu einer Neuerstellung des gesamten Betriebssystems führen muss (was natürlich nicht in einem laufenden System möglich ist).
Betriebssysteme mit einem Mikrokernel haben auch gewisse Nachteile; so führt z.B. die Verlagerung von Code in den User-Mode dazu, dass häufiger Kontextwechsel durchgeführt werden müssen (was den Rechner langsamer werden lässt). Manche Zugriffe auf die Hardware erfordern den privilegierten Kernel-Mode der CPU, was dann doch dazu führt, dass gewisse Treiber im Kernel-Mode laufen müssen.
Die bekanntesten Betriebssysteme mit einem Mikrokernel sind Mach (u.a. baut Mac OS X darauf auf) sowie Minix (ein von A. Tanenbaum für didaktische Zwecke entwickeltes Betriebssystem für die PC-Hardware) und QNX (ein kommerziell erhältliches Echtzeit-Betriebssystem für die PC-Hardware).
Typische Vertreter eines monolithischen Kernels sind UNIX bzw. Linux. Windows NT wurde ursprünglich auch als Mikrokernel entworfen, spätere Modifikationen führten allerdings dazu, dass man bei Windows nicht mehr von einem Mikrokernel sprechen kann.
In Multitasking-Betriebssystemen ist es notwendig, aus den bereiten Prozessen (sie haben den Zustand ready) den nächsten aktiven Prozess auszuwählen. Diese Aufgabe wird vom Scheduler ausgeführt und stellt eine der zentralsten Aufgaben des Betriebssystems dar. Sobald mehr als ein Prozess den Zustand ready besitzt, muss der Scheduler des Betriebssystems entscheiden, welcher Prozess die CPU erhält (wir gehen zur Vereinfachung von einem System mit nur einem Prozessor aus). Kriterien für einen "guten" Scheduler sind:
Bei Multitasking-Betriebssystemen werden zwei Grundsysteme für das Scheduling unterschieden:
Der aktive Prozess gibt von sich aus die CPU zu einem geeigneten Zeitpunkt frei. Es ist nur ein geringer Verwaltungsaufwand nötig. Es besteht jedoch die Gefahr, dass ein "unkooperativer" oder fehlerhafter Prozess alle anderen Prozesse blockiert.
Der Scheduler kann einem Prozess die CPU entziehen (z. B. ausgelöst durch einen Timer-Interrupt). Dadurch kann die Bearbeitung dringlicherer Aufgaben jederzeit begonnen werden (z. B. bei Echtzeit-Betriebssystemen). Ein fehlerhafter Prozess kann das System nicht blockieren. Preemptive Multitasking ist mittlerweile bei allen gängigen Betriebssystemen (auch bei Personalcomputern) Stand der Technik.
Anstoß für den Prozesswechsel durch Verdrängung:
Jeder Prozess erhält die CPU für eine bestimmte Zeitspanne (Zeitscheibe). Danach wird die CPU dem nächsten Prozess zugeteilt (Zeitscheibenverfahren, round robin scheduling).
Ein Prozesswechsel findet statt, wenn ein Ereignis (z. B. ein Hardwareinterrupt) einen anderen Prozess benötigt. Hier werden allgemein den einzelnen Prozessen Prioritäten zugeordnet, die sich dynamisch ändern. Ein bestimmtes Ereignis verleiht "seinem" Prozess eine höhere Priorität.
Bei kooperativem Multitasking oder ereignisgesteuerten Schedulern wird die Zuteilungsstrategie über Prioritäten gesteuert, wobei man beim kooperativen System von relativem Vorrang spricht (der erst nach Freigabe der CPU durch den aktiven Prozess wirksam wird) und beim ereignisgesteuerten System vom absoluten Vorrang (der sofort zum Prozesswechsel führt). Die Zeitscheibensteuerung kann als Sonderfall der Ereignissteuerung betrachtet werden, das Ereignis ist in diesem Fall der Ablauf der zugeteilten Zeitscheibe.
Einige Strategien, die in der Praxis verwendet werden, sind:
Verteilung der Prioritäten nach Ankunftszeit, ohne Vorrechte. Kommen zwei Prozesse genau gleichzeitig, wird eine zufällige Auswahl getroffen. Gute Systemauslastung, aber schlechtes Antwortzeitverhalten (lang laufende Prozesse behindern Kurzläufer). Einfach zu implementieren.
Jeder Prozess erhält eine feste Zeitspanne (time slice) zugeordnet. Nach Ablauf dieser Zeitspanne wird er verdrängt und der nächste Prozess erhält die CPU. Alle Prozesse haben immer die gleiche Priorität. Die Zeitspanne kann konstant sein oder abhängig von der Prozessorbelastung variieren. Kurze Antwortzeiten bei kleinen Zeitscheiben, aber dann höhere Verluste durch die häufigen Kontextwechsel.
Jedem bereiten Prozess wird eine Priorität zugeordnet. Vergabe der CPU in absteigender Priorität. Ein Prozess niedrigerer Priorität kann die CPU erst erhalten, wenn alle Prozesse höherer Priorität abgearbeitet sind. Ein bereit werdender Prozess höherer Priorität verdrängt einen aktiven Prozess niedrigerer Priorität. Alle Prozesse gleicher Priorität werden i.a. in jeweils einer eigenen Warteschlange geführt.
Die Realisierung kann durch mehrere unterschiedliche Verfahren erfolgen, zum Teil gemischt mit anderen Strategien, z.B.
In Dialogsystemen wird normalerweise Round Robin verwendet, um den Benutzern akzeptable Antwortzeiten zu bieten. Bei Batchbetrieb und gemischten Systemen kommen oft Kombinationen der erwähnten Strategien vor (z.B. getrenntes Scheduling für Dialog- und Batchbetrieb).
Jeder Prozess (oder Thread) muss einen lokalen Datenbereich besitzen, da es durchaus vorkommen kann, dass ein Prozess oder Thread von mehreren anderen aus gestartet werden kann (z. B. die Benutzershell bei einem Multiusersystem). Insbesondere dürfen Betriebssystemdienste keine globalen Speicherbereiche verwenden, da diese von allen laufenden Prozessen aufgerufen werden können und sonst bei der Prozessumschaltung Werte des verdrängten Prozesses durch den Betriebssystem-Aufruf des nun aktiven Prozesses überschrieben würden. Man nennt diese Eigenschaft Wiedereintrittsfähigkeit (engl. reentrance).
Manche Singletasking-Betriebssysteme (z. B. MS-DOS) sind nicht reentrant und daher nicht oder nur schwer auf Multitaskingbetrieb erweiterbar.
Jeder Prozess erhält eine feste Zeitscheibe. Die Prozesse können untereinander nicht kommunizieren (außer auf dem Umweg über das Betriebssystem). Ereignisse (z. B. Mausbewegung) werden von Betriebssystem bearbeitet und den Prozessen gemeldet.
Kooperatives Multitasking. Ein Prozess kann eine "öffentliche" Nachrichten senden, die dann von einem anderen Prozess aufgenommen und beantwortet werden kann (Client-Server-Prinzip). Für Ereignisse (z. B. Mausbewegung) existieren jeweils einzelne Prozesse. Der Betriebssystem-Kern stellt nur eine Schnittstelle für Systemaufrufe zur Verfügung.
Modernes Single-User- Multi-Tasking-Betriebssystem. Preemptive Multitasking. Die Kommunikation der Prozesse untereinander funktioniert prinzipiell wie bei Windows ab 3.1. Jedoch überwacht das Betriebssystem die Kommunikation der Prozesse und kann sie gegebenenfalls verhindern. Einzelne Prozesse können in mehrere Threads aufgeteilt werden.
Zeitscheibenverfahren für alle Prozesse. Zusätzlich können alle Prozesse mit dem Betriebssystemkern kommunizieren. Ereignisse werden vom Betriebssystemkern an die Prozesse weitergereicht.
Zeitscheibenverfahren mit Prioritätssteuerung. Diverse Möglichkeiten der IPC. Der Betriebssystemkern verarbeitet alle Ereignisse und "weckt" den Prozess auf, dem das Ereignis zugeordnet ist. Zeitscheiben sind je nach Bedarf unterschiedlich lang. Je nach Variante von Unix gibt es auch Multithreading. Zusätzlich ist ein Multiuserbetrieb möglich.
Realzeitbetriebssysteme arbeiten in der Regel mit Zeitscheibenverfahren, wobei zusätzliche Bedingungen hinzukommen. Ereignisse (in der Regel Hardware- oder Software-Interrupts) müssen innerhalb einer bestimmten Sollzeit bearbeitet werden (Echtzeitbedingung). Daher findet sich hier häufig eine Aufteilung der Programme in einzelne Threads (bei Realzeitbetriebssystemen auch oft "Task" genannt).
In Multitasking-Betriebssystemen kommt es immer wieder vor, dass sich verschiedene Prozesse gemeinsame Betriebsmittel ("Ressourcen") teilen müssen (beispielsweise einen gemeinsam benützten Speicherbereich zum Datenaustausch). Bei gleichzeitigem Zugriff zweier Prozesse auf diese Betriebsmittel kann es zu Inkonsistenzen der Daten kommen, die möglicherweise selten auftreten und dadurch sehr schwer aufzuspüren sind.
Kooperierende Prozesse müssen daher wegen der zwischen ihnen vorhandenen Abhängigkeiten miteinander synchronisiert (koordiniert) werden. Prinzipiell lassen sich zwei Klassen von Abhängigkeiten unterscheiden:
Ohne eine solche Sperrung entstehen Datenverluste, z.B. im folgenden Fall:
Damit bleibt die Änderung X(0) nach X(1) aus dem Prozess A unberücksichtigt.
Oder auch bei folgendem Beispiel:
Die Folge ist: Prozess A überschreibt den Dateinamen, den Prozess B in der Spooler-Warteschlange auf Position 8 eingetragen hatte. Diese Datei wird vom Spooler "vergessen".
Solche Situationen heißen zeitkritsche Abläufe. Programmabschnitte, die auf gemeinsam benutzte Daten zugreifen, heißen kritische Abschnitte (critical sections).
Fehler in zeitkritischen Abläufen sind sehr schwer erkennbar, da sie nur sehr selten auftreten. Solche zeitkritische Abläufe treten vermehrt zwischen den Threads eines gemeinsamen Prozesses auf, da gerade dort die Benützung gemeinsamer Betriebsmittel zu erwarten ist.
Fehler in kritischen Abschnitten können nur durch wechselseitigen Ausschluss der beteiligten Prozesse oder Threads vermieden werden. Kritische Abschnitte treten überall auf, wo zwei oder mehr Prozesse/Threads auf einem Computer oder in einem Netz um mindestens eine Ressource konkurrieren, die sie schreibend benutzen wollen.
Vier Bedingungen für eine gute Lösung (nach Andrew S. Tanenbaum):
Die letzten beiden Punkte dienen der Stabilität, sie sollen Prozessverklemmungen verhindern.
Der folgende Link stellt Beispiele für zeitkritische Abläufe vor.
Einige Möglichkeiten der Interprocess Communication (IPC):
|
|
|
|