
Relationale Datenbanken
Begriffe
Eine Datenbank ist eine systematisch strukturierte, langfristig verfügbare Sammlung von Daten einschließlich der zur sicheren Manipulation dieser Daten erforderlichen Software. Diese Software wird gelegentlich DBMS (Data Base Management System) genannt.
Man unterscheidet:
Sequentielle Datenbank
Die Daten werden sequentiell, d.h. nacheinander, durch Listentrennzeichen voneinander getrennt, gespeichert. (CSV-Dateiformat, Comma Separated Value) Das Verfahren ist älter und eignet sich heute nur für kleine Datenbanken wie persönliche Adressbücher.
Relationale Datenbank (E. F. CODD 1970)
Die Daten werden in sogenannten Relationen, das sind Tabellen gespeichert. Die Tabellenspalten heißen Felder, die Zeilen heißen Datensätze.
|
Vorname |
Familienname |
Wohnort |
|
Petra |
Müller |
Wien |
|
Walter |
Langbein |
Graz |
Relationale Datenbanken bestehen ab einer bestimmten Komplexität in der Regel aus mehreren Tabellen, die über Beziehungen (Relationships) miteinander verknüpft sind. Für das Auslesen von Daten, auch solcher, die auf mehrere Tabellen verteilt sind, werden Abfragen (Query) verwendet, die die Daten allerdings nicht kopieren, sondern lediglich über Pointer auf diese zugreifen. Die Benutzerschnittstelle am Client heißt Formular, Clients zur Erzeugung von hardcopies heißen Bericht.
Kleinere Datenbanksysteme wie Microsoft Access oder MySQL (Linux) legen alle Datenbankobjekte in einer Datei ab, bei größeren Client/Server-Systemen wie Oracle oder postgreSQL (Linux) liegen Tabellen und Abfragen am Server, während Formulare und Berichte von der Software des Clients erstellt werden. Windowsclients verwenden in der Regel
ODBC (Open DataBase Connectivity),
eine standardisierte Softwareschnittstelle von Microsoft, über die Anwendungsprogramme auf unterschiedliche Datenbanken (Client/Server) zugreifen können.
Als Standard über Datenbanksysteme verschiedener Hersteller hinweg fungiert
SQL (Structured Query Language),
eine systemunabhängige Sprache zur Erstellung, Manipulation und Abfrage von (relationalen) Datenbanken.
Vor allem bei größeren Datenbanksystemen sind Ordnungsprinzipien wesentlich, die garantieren, dass die Benutzer garantiert richtige Ergebnisse auf ihre Anfragen erhalten.
Zu vermeiden sind im Besonderen:
Redundanz
Redundanz ist in einem Datenbestand genau dann vorhanden, wenn ein Teil der Daten ohne Informationsverlust weggelassen werden kann. Das ist etwa dann der Fall, wenn der Name in mehreren Feldern eines Datenbanksystems abgelegt wird, oder Sozialversicherungsnummen und Geburtsdatum in verschiedenen editierbaren Feldern abgelegt sind.
| Familienname |
GebDat |
SVNR |
| Müller |
1.4.1990 |
1234010490 |
| Langbein |
23.10.1985 |
4321231085 |
Inkonsistenz
liegt vor, wenn es zu gleichen Daten unterschiedliche Schreibweisen gibt. (z.B.: "r.k.", "röm.kath.")
Anomalien
Anomalien sind unerwünschte Verhaltensweisen eines Datenbanksystems, wenn Lösch- oder Einfüge- oder Aktualisierungsoperationen über mehrere Tabellen hinweg stattfinden. Beim Streichen eines Kunden sollten wahrscheinlich alle Rechnungsinformationen zur weiteren buchhalterischen Verwendung erhalten bleiben.
ER - Entity-Relatioship Modell
Der Planung einer Datenbank dient das ER-Modell (Peter Chen 1976), das folgende Begriffe verwendet:
Entity(Entität):
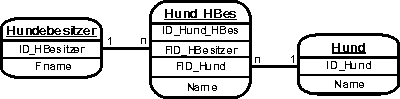
Das ist ein in einer Datenbank abzubildendes reales Objekt. Eine Datenbank, die mehrere Hunde und deren Besitzer listet, wird wohl die Entitäten Hund und Hundebesitzer enthalten. In der Umsetzung werden aus den Entitäten dann Tabellen. Diese Entitäten enthalten
Attribute (Felder),
die die Eigenschaften der Entitäten enthalten. Im Beispiel werden Hundebesitzer wohl das Attribut Familienname enthalten und Hund könnte ein Attribut Name haben. Ein Attribut, der
Primärschlüssel
ist ausgezeichnet; es gestattet in der Umsetzung die eindeutige Indentifizierung jedes Datensatzes und ist in der Regel eine Zahl. Zwischen den Entitäten besteht eine
Relationship (Verknüpfung),
die den Zusammenhang beschreibt.
Bei den Verknüpfungen gibt es:

Normalisierung
Um Redundanzen, Inkonsistenzen und Anomalien zu vermeiden oder zu beseitigen, gibt es sogenannte Normalformen von Datenbanken. Es handelt sich dabei um ein theoretisches Regelwerk, das schrittweise auf unstrukturierte Daten angewendet werden kann. Die Vorgangsweise selbst ist algorithmisch, sodass das Normalisieren von Datenbanken auch schon von Software unterstützt werden kann. Das Normalisieren führt in der Regel zu komplexeren Datenbankstrukturen, die jeweils hinsichtlich der gewünschten Funktionalität zu hinterfragen sind. Für wenige Datensätze, die in einer überschaubaren Anzahl von Feldern liegen wird man daher, aller Theorie zum Trotz, mit einer Entität oft das Auslangen finden. Wir gehen anhand eines einfachen Beispiels vor:
Wir betrachten die folgende Tabelle, die Hunde und deren BesitzerInnen auflistet, wobei der Schäferhund Rex zwei Besitzer haben soll:
| Name |
Name |
Rasse |
| Müller Werner |
Rex, Waldi |
Schäfer, Dackel |
Langbein Angelika |
Wastl |
Dackel |
| Müller Lisa |
Rex |
Schäfer |
1.Normalform
Die Widersprüche der gegebenen Tabelle zur 1.Normalform sind augenscheinlich. Da ein Aufteilen in mehere Entitäten nicht zwingend ist erhalten wir die Entität Person_Hund in der 1.Normalform:
| HBesitzer_Hund
|
||||
| ID_HBesitzer_Hund |
VName |
FName |
HName |
Rasse |
| 1 |
Werner |
Müller |
Rex |
Schäfer |
| 2 |
Werner |
Müller |
Waldi |
Dackel |
| 3 |
Angelika |
Langbein |
Wastl |
Dackel |
| 4 |
Lisa |
Müller |
Rex |
Schäfer |
Wir erkennen mehrere Unzulänglichkeiten:
2.Normalform
Eine Entität befindet sich in der 2.Normalform, wenn
Wir halten fest, dass HName und Rasse nicht vom Primärschlüssel abhängen. Das kann dadurch bereinigt werden, dass eigene Entitäten für Hund und Rasse, unter Berücksichtigung der Regeln der 1. und 2.Normalform eingefügt werden. Damit ergeben sich die folgenden Tabellen:
| HBesitzer
|
Hund |
Rasse |
||||||
| ID_HBesitzer |
VName |
FName |
ID_Hund |
HName |
ID_Rasse |
Rasse |
||
| 1 |
Werner |
Müller |
1 |
Rex |
1 |
Schäfer |
||
2 |
Lisa |
Müller |
2 |
Waldi |
2 |
Dackel |
||
| 3 |
Angelika |
Langbein |
3 |
Wastl |
||||
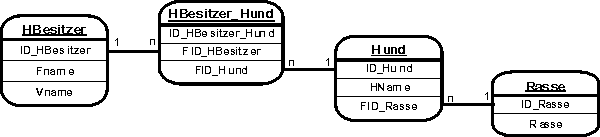
Nun sind weder die Besitzverhältnisse noch die Rassen der Hunde ablesbar. Da einerseits Werner Müller Rex und Waldi besitzt und anderseits Rex Werner und Lisa Müller gehört, ist zwischen Person und Hund eine m:n Beziehung zu konstruieren. Da Waldi und Wastl Dackel sind, muss zwischen Rasse und Hund eine 1:n Beziehung gesetzt werden, um Redundanzen zu vermeiden. Außerdem ist die Rasse nicht vom Primärschlüssel der Entität Hund abhängig und daher mit Blick auf die 3.Normalform eine Entität Rasse zu konstruieren. Wir erhalten also vier Tabellen, die Besitzverhältnisse werden über Beziehungen auf Fremdschlüsselfelder geregelt:
| HBesitzer
|
HBesitzer_Hund |
Hund
|
Rasse |
||||||||||
|
ID_HBesitzer |
VName |
FName |
ID_HBesitzer_Hund |
FID_HBesitzer |
FID_Hund |
ID_Hund |
HName |
FID_Rasse |
ID_Rasse |
Rasse |
|||
|
1 |
Werner |
Müller |
1 |
1 |
1 |
1 |
Rex |
1 |
1 |
Schäfer |
|||
|
2 |
Lisa |
Müller |
2 |
1 |
2 |
2 |
Waldi |
2 |
2 |
Dackel |
|||
|
3 |
Angelika |
Langbein |
3 |
3 |
3 |
3 |
Wastl |
2 |
|||||
4 |
2 |
1 |
|||||||||||
Die Datenbank hat damit im ER-Modell folgendes Design:
3.Normalform
Eine Entität befindet sich in der 3.Normalform, wenn
Die dritte Normalform ist hier erfüllt. Der Vollständigkeit halber sei erwähnt, dass es bei sehr theoretischem Zugang fünf Normalformen gibt.